- 1. 非监督学习
- 4. 将点与聚类匹配
- 5. 优化中心(橡皮筋)
- 6. 移动中心
- 9. K-均值聚类可视化
- 12. Sklearn中的聚类
- 14. K-均值的局限
- 15. 反直觉的聚类
- 18. K-均值聚类迷你项目 - 部署聚类
- 19. 使用 3 个特征聚类
- 22. 股票期权范围
1. 非监督学习
- unsupervised learnings 非监督学习
- clusteing 聚类
- dimensionality reduction 降维
我们有一些问题,但是不知道答案,我们要做的无监督学习就是按照他们的性质把他们自动地分成很多组,每组的问题是具有类似性质的(比如数学问题会聚集在一组,英语问题会聚集在一组,物理……..)
所有数据只有特征向量没有标签,但是可以发现这些数据呈现出聚群的结构,本质是一个相似的类型的会聚集在一起。把这些没有标签的数据分成一个一个组合,就是聚类(Clustering)。比如Google新闻,每天会搜集大量的新闻,然后把它们全部聚类,就会自动分成几十个不同的组(比如娱乐,科技,政治……),每个组内新闻都具有相似的内容结构。
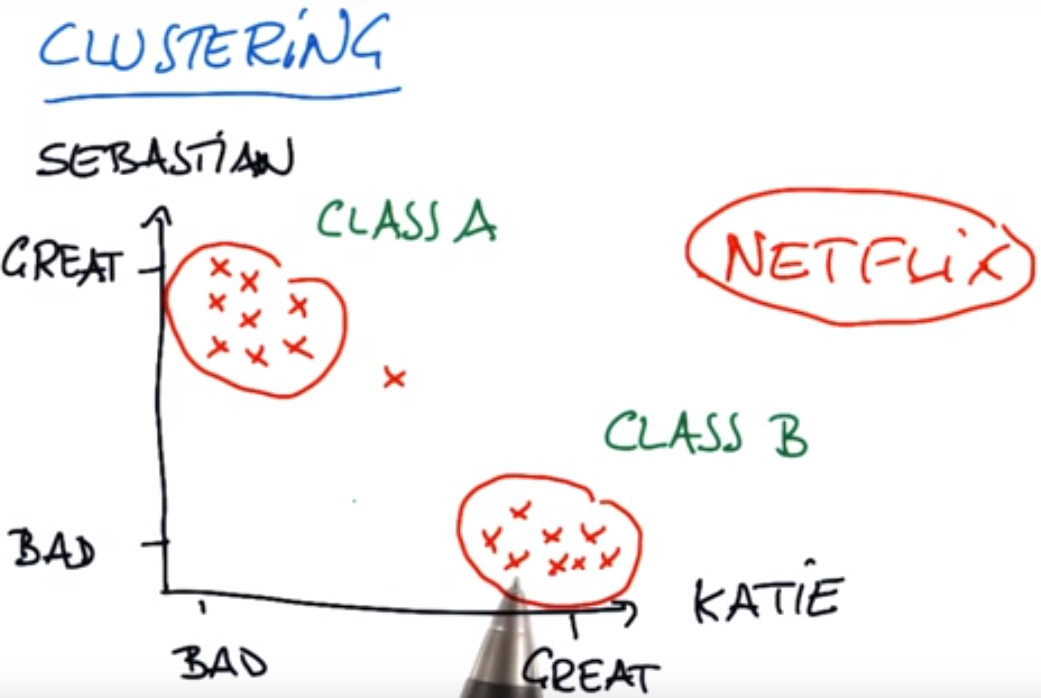
下面是Netflix针对两人对不同类别电影的评级给出的聚类,从而根据不同人推荐不同的电影:
4. 将点与聚类匹配
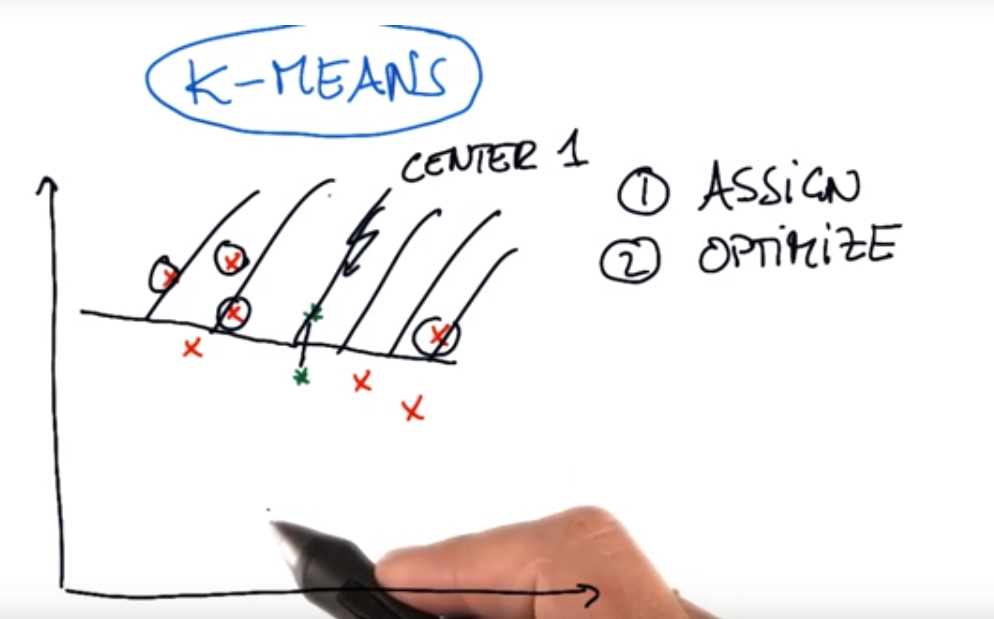
- 第一步先分配,即随机分配聚类中心点
- 第二步,再优化,利用下面的最短距离和方法,不断移动聚类中心点
- 绿色点假设是聚类中心,判断哪些红色点与中心点1距离,比中心点2的距离更短:
5. 优化中心(橡皮筋)
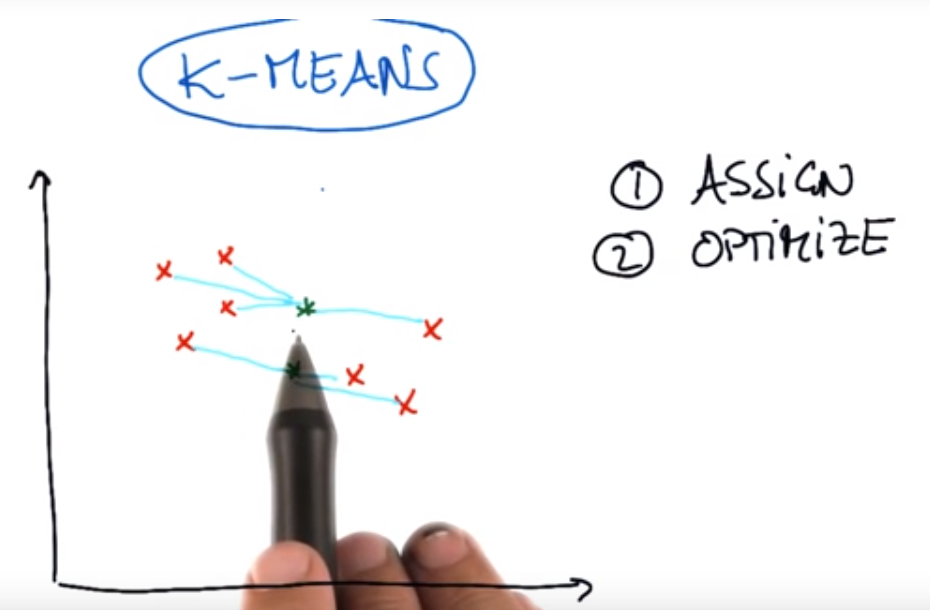
在优化步骤中,我们移动绿色的集群中心点,使得蓝色橡皮筋的总长度最小。
6. 移动中心
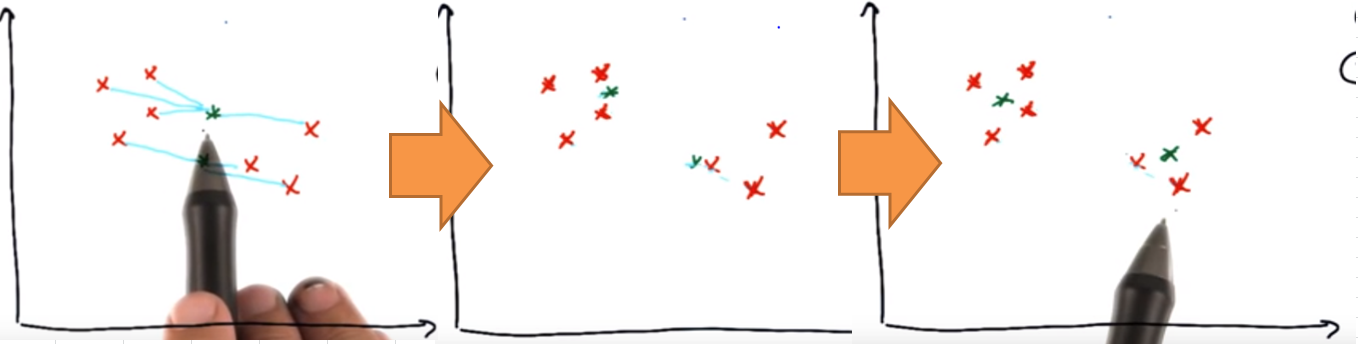
下面是两次中心的移动过程,经过这两次移动,聚类中心就正确了,与各聚类中点的距离最小了:
9. K-均值聚类可视化
参考K-均值聚类
12. Sklearn中的聚类
参考Clustering 和 sklearn.cluster.KMeans
class sklearn.cluster.KMeans(n_clusters=8, init=’k-means++’, n_init=10, max_iter=300, tol=0.0001, precompute_distances=’auto’, verbose=0, random_state=None, copy_x=True, n_jobs=1, algorithm=’auto’)
n_clusters:聚类数量,一般要根据实际情况设置-
max_iter=300:移动的最大次数,一般在300次之前就已经找到最好的中心了 - 示例如下:
>>> from sklearn.cluster import KMeans
>>> import numpy as np
>>> X = np.array([[1, 2], [1, 4], [1, 0],
... [4, 2], [4, 4], [4, 0]])
# 2 个聚类,对X数据进行训练
>>> kmeans = KMeans(n_clusters=2, random_state=0).fit(X)
# 上面训练出来的标签
>>> kmeans.labels_
array([0, 0, 0, 1, 1, 1], dtype=int32)
# 预测新的数据
>>> kmeans.predict([[0, 0], [4, 4]])
array([0, 1], dtype=int32)
# 2个聚类的中心点
>>> kmeans.cluster_centers_
array([[ 1., 2.],
[ 4., 2.]])
14. K-均值的局限
因为K-均值是所谓的爬山算法,同一个训练集训练出来的模型,因为初始聚类中心点的不同,可能会预测不同的结果。
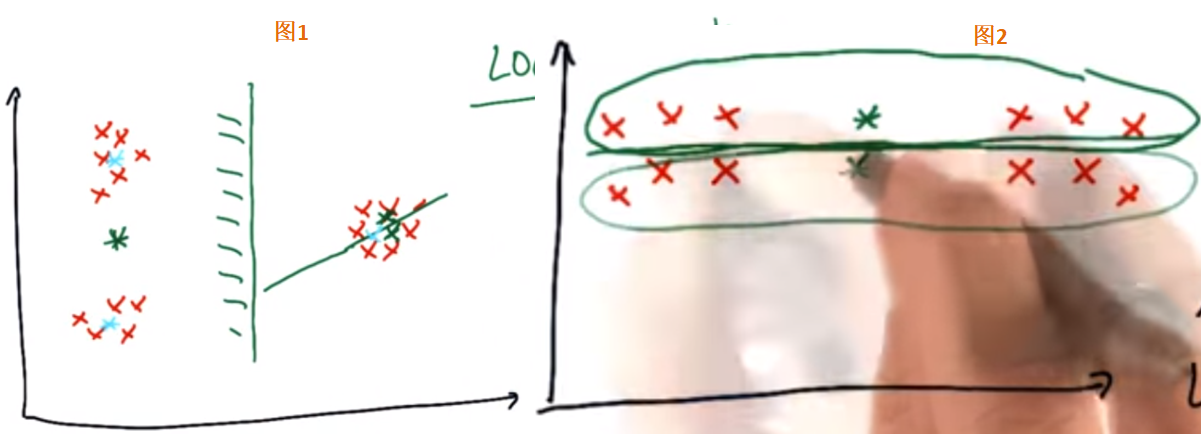
15. 反直觉的聚类
如下图,因为初始中心点的位置,可能会导致如下的分类,
- 图1,浅蓝色是期望的聚类中心,但是可能会变成深绿色的聚类
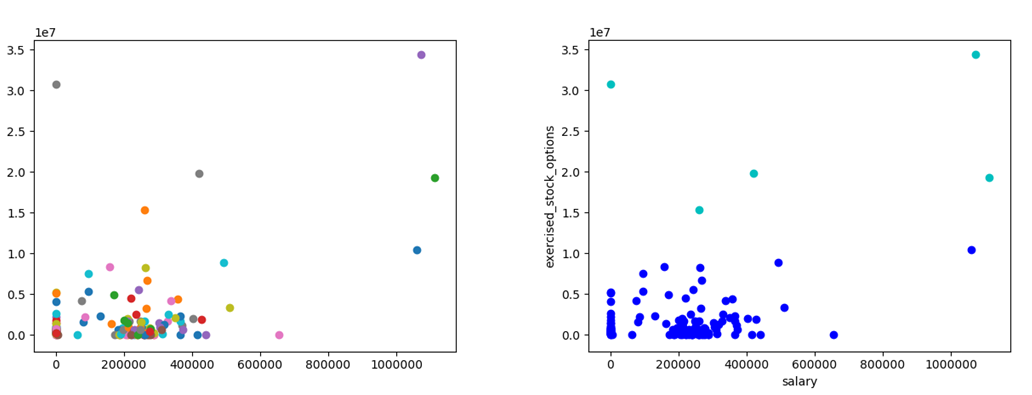
18. K-均值聚类迷你项目 - 部署聚类
在 financial_features 数据上部署 k-均值聚类,并将 2 个聚类指定为参数。将聚类预测存储到名为 pred 的列表,以便脚本底部的 Draw() 命令正常工作。
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters=2, random_state=0).fit(finance_features)
pred = kmeans.labels_
- 图形
19. 使用 3 个特征聚类
向特征列表(features_list)中添加第三个特征:“total_payments”。现在使用 3 个,而不是 2 个输入特征重新运行聚类(很明显,我们仍然可以只显示原来的 2 个维度)。将聚类绘图与使用 2 个输入特征获取的绘图进行比较。
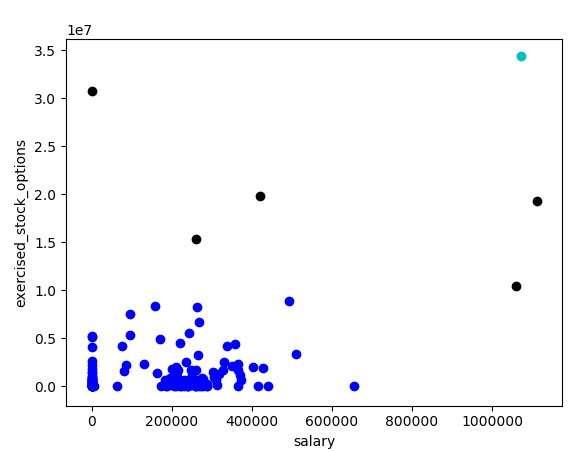
对比上面的图形,有四个点的聚类发生了变化。
22. 股票期权范围
“exercised_stock_options”的最大值和最小值(忽略“NaN”)
data_find = []
for k,v in data_dict.items():
value = v["exercised_stock_options"]
if value != "NaN":
data_find.append(value)
data_find.sort()
print data_find[0]
print data_find[-1]
结果如下:
3285
34348384
下一节的薪酬范围“salary”,相同的计算方式,结果为:
477
1111258