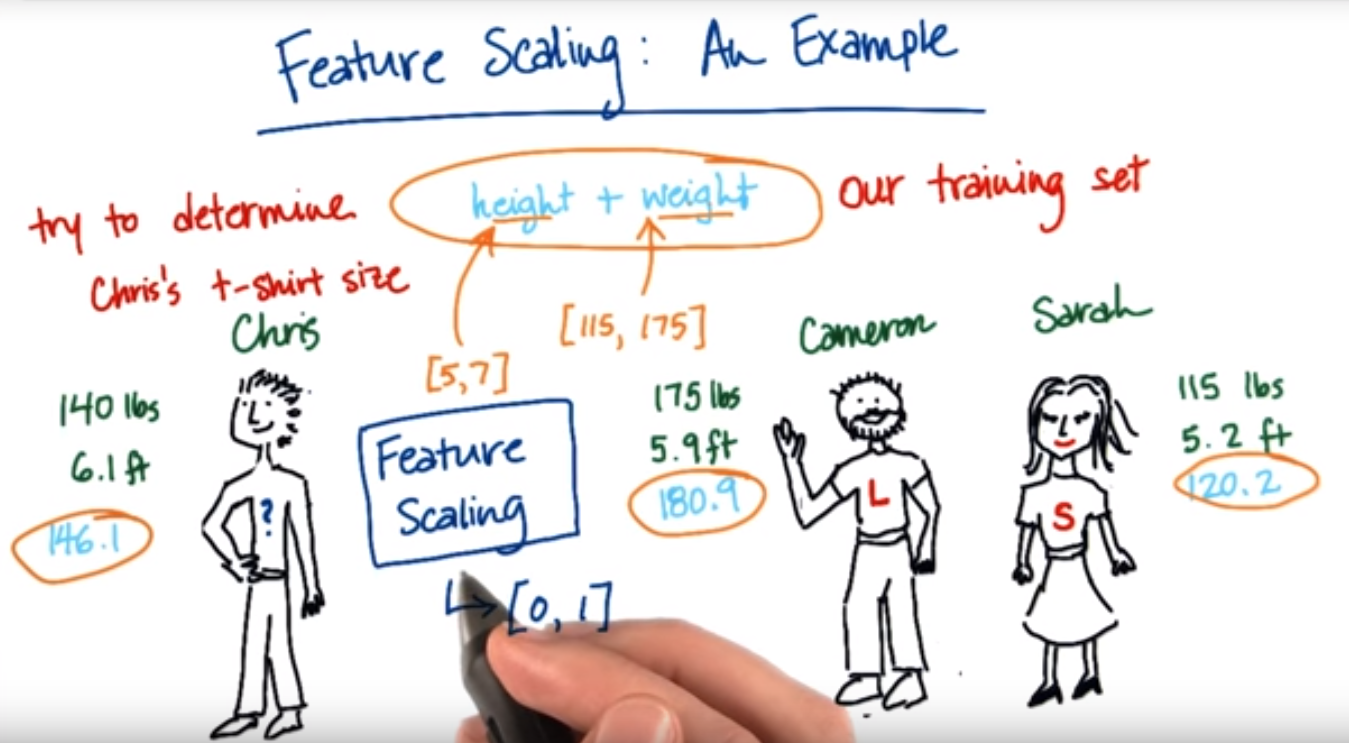
6. 利用不同的尺度来比较特征
为什么要进行尺度的缩放,请看下面的例子:
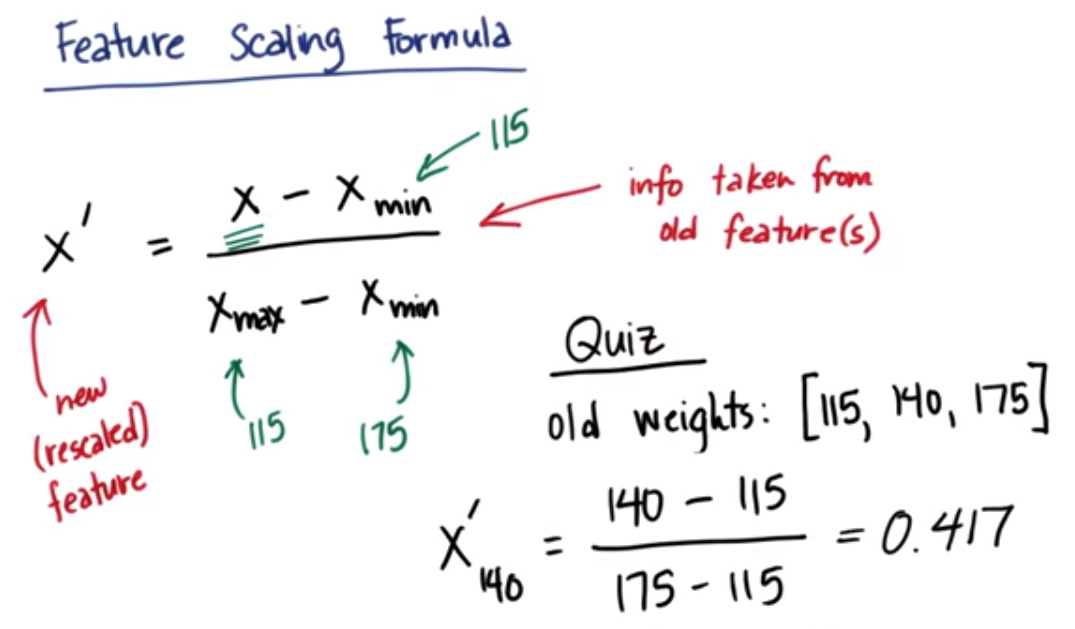
9. 特征缩放公式练习
10. 最小值/最大值重缩放器编码练习
def featureScaling(arr):
arr.sort()
# 避免所有值都是相同的情况
if arr[0] == arr[-1]:
return 1
new_arr = []
for i in arr:
new_data = float(i-arr[0])/(arr[-1]-arr[0])
new_arr.append(new_data)
return new_arr
# tests of your feature scaler--line below is input data
data = [115, 140, 175]
print featureScaling(data)
输出结果为:
[0.0, 0.4166666666666667, 1.0]
Good job! Your output matches our solution.
11. sklearn 中的最小值/最大值缩放器
参考sklearn.preprocessing.MinMaxScaler
>>> from sklearn.preprocessing import MinMaxScaler
>>> data = [[-1, 2], [-0.5, 6], [0, 10], [-3, 18]]
>>> scaler = MinMaxScaler()
>>> print scaler.fit(data)
MinMaxScaler(copy=True, feature_range=(0, 1))
>>>
>>> print scaler.data_max_
[ 0. 18.]
>>> print scaler.data_min_
[-3. 2.]
>>> print scaler.transform(data)
[[ 0. 0. ]
[ 0.25 0.25]
[ 0.5 0.5 ]
[ 1. 1. ]]
>>>
>>> print scaler.transform([[2,2]])
[[ 1.5 0. ]]
12. 需要重缩放的算法练习
哪些机器学习算法会受到特征缩放的影响?
- 决策树
- [★影响]使用 RBF 核函数的 SVN
- 线性回归
- [★影响]K-均值聚类
决策树是针对每个特征分别进行判断,比如通过年龄进行判断时,如果单位是月份,5岁以上就是60月以上,以年为单位,5岁以上就是5年,虽然判断单位变了,但是最终判断的结果不变。
线性回归,回归方程式为 y = ax1 + bx2 + c*x3 + m ,如果x1缩小一半,那对应系数a就会增加一倍,所以整体没有变化,故特征缩放对其没有影响。
但是SVN和k均值聚类,都是要计算特征点到线之前的距离,如果特征值发生缩放,则距离值发生变化,最终分类也会有变化。